Technical SEO explanation
Technical SEO is the process of optimising your website to help search engines find, understand, and index your pages.
Although search engines are pretty good at finding and understanding content on a website, they are not perfect. Technical issues can prevent them from crawling, indexing, and showing web pages in the search results.
Having an SEO agency audit your website for technical SEO is a great idea, but if you do not want to pay a specialist to do this, here is what you need to know.
The 7 main factors of technical SEO
If your site is struggling to rank or dropping organic positions in search engines, most of the time it is down to a technical SEO reason.
We will show you 7 of the most critical factors of technical SEO, of course, there are a lot more things involved with technical SEO, but we want to cover the main items for your technical SEO checklist.
1.
Content is crawlable and indexable
Crawling is how search engines discover most new content. It’s where the spiders visit and download new data from known pages or posts.
For example, let’s say you add a new page to your site and link to it from your homepage. When Google next crawls your homepage, it’ll discover the link to the new page. Then, if it decides the content on that page is valuable for searchers, it’ll get indexed.
This process works ok, as long as the search engines are not getting blocked from crawling or indexing a page.
The robots.txt is the file that tells search engines like Google which pages they can and can’t crawl. You can view it by navigating to yourdomain.com/robots.txt.
The robots.txt file can be a problematic and costly issue if not dealt with in the right way, so make sure you check it and fix any problems. You can check if any pages are blocked by robots.txt in Google Search Console. Just go to the Coverage report, toggle to view any excluded URLs, then look for the blocked by robots.txt error.
If there are any URLs in there that shouldn’t be blocked, you’ll need to remove or edit your robots.txt file to fix the issue.
However, crawlable pages aren’t always indexable. If your webpage has a meta robots tag or x‑robots header set to “noindex,” search engines won’t be able to index the page.
Fix these by removing the ‘noindex’ meta tag or x‑robots-tag for any pages that should be indexed.
Resources & further reading
2.
HTTPS
HTTPS encrypts data sent between a website and the visitor. It helps protect sensitive information from being compromised during data transfer. HTTPS has been a ranking factor since 2014 and although not a massive one, it is needed for 99% of the payment gateways for e-commerce stores and is pretty much essential anyway now in 2026.
If you see a red “Not Secure” warning, you’re not using HTTPS, and you need to install an SSL certificate. You can get one for free from LetsEncrypt or if you are using our web hosting, we have a free shared SSL certificate included with all hosting accounts. Alternatively, we have a professional Rapid SSL with a dedicated IP address that you can purchase separately.
If you have an SSL certificate and still see the “Not Secure” warning then you have a mixed content issue. That means the page itself is loading over HTTPS, but it’s loading resource files (images, CSS, etc.) over HTTP. If you are using WordPress then we would suggest you use the Velvet Blues plugin, to change the domain part of your URL for media & links.
This is what you want to see, the padlock.
![]()
Resources & further reading
3.
Duplicate content
Duplicate content is where the same or very similar content appears in more than one place on your website. It can happen on your website or content copied from other websites.
Duplicate content can cause other issues like:
- Unfriendly URLs in search results.
- Backlink dilution.
- Devalued power from links pointing to duplicate content.
- Wasted Google crawl budget.
You can see problems with duplicate content issues in Google Search Console. Go to Coverage, click to view any excluded URLs.
It is important that you use the canonical element to let search engines know where the “main” version of your content is.
Having similar content on geographical pages that cover the same subject matter but for different towns/cities, has generally been considered ok, but ideally not recommended to do.
Resources & further reading
4.
Website speed
Website speed on desktops since 2010, and on mobile in July 2018 has been classified as a verified ranking factor in Google.
Websites or pages that load slowly are annoying for visiting traffic and site owners, which is why Google made page speed a ranking factor.
There are many tools to benchmark website speeds and Google Pagespeed Insights is a great place to start. It will give you a performance score from 0-100 on desktop and mobile. It will also provide what is causing the issues on your site and to some extent how to fix these things.
Some processes that will have a positive impact on your page speed are:
- Install a caching plugin – If you are using WordPress, there are 2 options here in our opinion, NitroPack and WP Rocket. You can read full reviews of these products below in the resources block.
- Switch to a faster DNS – Just sign up for a free account with Cloudflare and then swap your nameservers at the domain registrar level. Beware though, the free Cloudflare does have limitations if you have lots of traffic already, it may be worth investing in the paid plan.
- Image compression – Images are usually the largest files on a website along with videos. Compressing them reduces their size and ensures they load faster. There are lots of image compression plugins available, the best ones are Imagify and Shortpixel for WordPress.
- CDN – CDN’s do work, but are a little overkill in our opinion. CDNs are great if you have a big site and a lot of traffic coming from international locations. A good free option with its limitations is again Cloudflare, but probably the best premium option is Cloudways. A great video to setup Cloudways was made by Adam Preiser over at WP Crafter.
- Minify HTML, CSS & JS – Minification removes whitespace from a website’s code to reduce file sizes. WP Rocket has features built in to achieve this.
Resources & further reading
5.
Schema
Schema markup is code that helps search engines understand your content and better represent it in search results. Schema can do more than help you with SEO though.
Schema powers rich snippets which in some cases have much higher clickthrough rates than organic results. That means more traffic to your site, depending on the quality of the content in the schema.
3 reasons why Google likes schema
- It understands schema better than plain text.
- Searchers get more relevant results.
- Your website may appear in rich snippets and can become an entity in Google’s Knowledge Graph.
Schema markup is a crucial part of structured data that makes the semantic web and search viable. Websites can portray easier the actual meaning of their content to crawlers.
Schema example
A good example of schema in action is the review stars you see in search results.
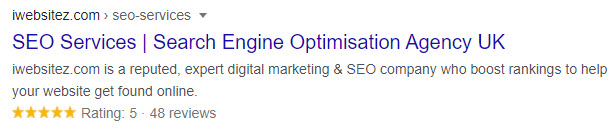
So schema can play a big role in technical SEO and should be implemented by professionals and not undertaken if you don’t know how to.
With WordPress websites, the best plugin for schema structured data by far is Schema Pro. If this of interest, please see the review link in the resources section below.
Resources & further reading
6.
Orphaned pages
Orphaned pages that have no internal links from pages/content on your website is quite a big problem, as search engines can’t find them unless they have been linked to from other websites.
It’s often difficult to find orphaned pages with most auditing tools, as they crawl your site much like search engines do. However, you download a free tool called Screaming Frog which will help you to find these orphaned pages.
If any of the URLs are important to you, you should link to them from your navigation or from relevant already popular pages. If they are not that important to you, then delete or redirect them to more popular pages.
Resources & further reading
7.
Broken links
Broken links are links on your site that point to non-existent resources that are either internal pages on your domain or outgoing links to other websites. These can be frowned upon by search engines as too many broken links on a website will lead the search engines to assume that your site is untrustworthy and a poor resource for information.
Again, the Screaming Frog Spider tool comes in to play helping you to find these broken links on your website. As soon as you locate any broken links, fix them immediately.
If you are using WordPress, an awesome plugin is the Broken Link Checker by WPMU Dev. It automatically scans for broken links and directs you where they are so you can fix straight away.
Resources & further reading
Technical SEO summary
Technical SEO is a complex discipline, and there are many more best practices that we didn’t have time to cover in this article. The checklist above is usually enough to solve the most common technical website mistakes and put your site’s performance amongst the top echelons of the internet.
If you want us to take care of your SEO for your website, technical SEO is part of the process, so safely assume all of the above and more will be taken care of.
Useful resources
Technical SEO FAQ
Why is technical SEO important?
Technical SEO is important because it helps search engines understand your content that it may deem valuable to your potential website visitors. This is crucial because it could tempt the search engine to rank you higher in organic search, as your content is more understandable than other potential sites. Creating this technical foundation within your website will go a long way to satisfy your visitors and search engines.
Is technical SEO a skill?
Technical SEO is a very unique skill in a person’s toolbox. Optimising for search and especially technical SEO is classified as a skill as this cannot just be learnt from YouTube.
It takes time to perfect technical SEO and only when you have experience will you know if something goes wrong with things you do, the most important thing to know is how to solve the problem.
Some of our posts contain affiliate links. That means if you buy something after clicking a link we may receive commission at no extra cost to you. Thank you for supporting our site!
